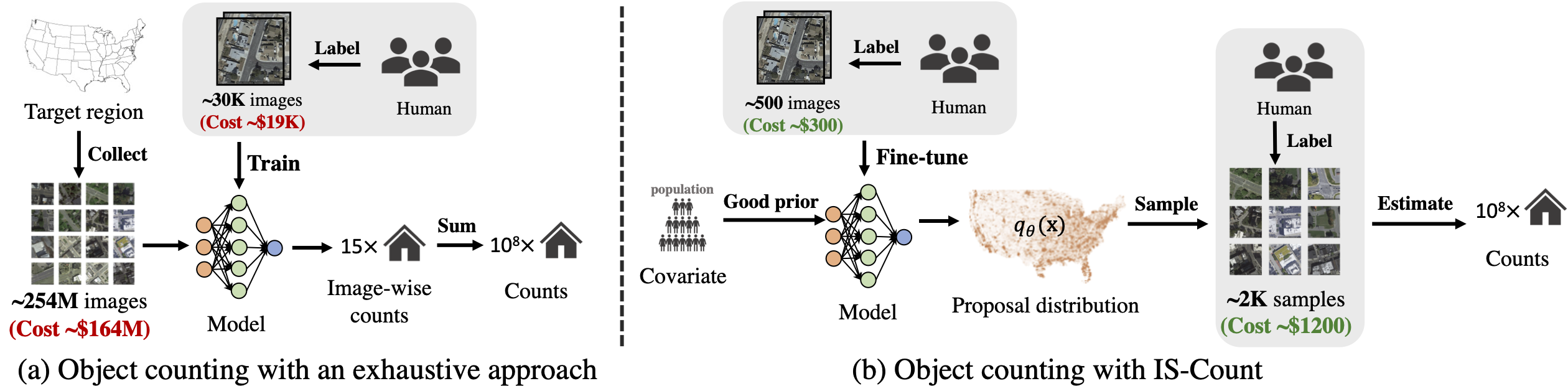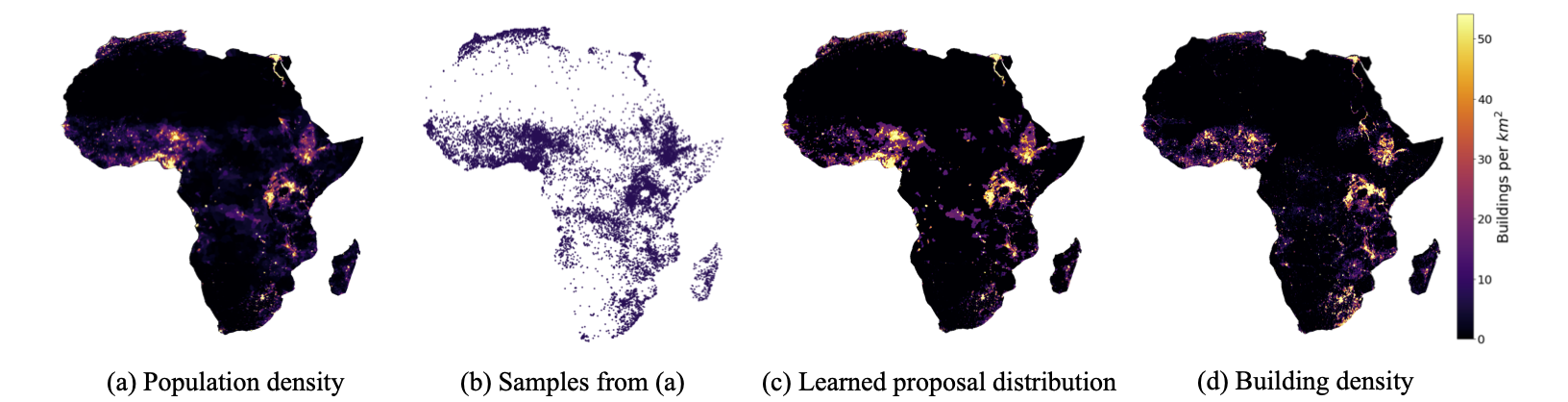
Object detection in high-resolution satellite imagery is emerging as a scalable alternative to on-the-ground survey data collection in many environmental and socioeconomic monitoring applications. However, performing object detection over large geographies can still be prohibitively expensive due to the high cost of purchasing imagery and compute. Inspired by traditional survey data collection strategies, we propose an approach to estimate object count statistics over large geographies through sampling. Given a cost budget, our method selects a small number of representative areas by sampling from a learnable proposal distribution. Using importance sampling, we are able to accurately estimate object counts after processing only a small fraction of the images compared to an exhaustive approach. We show empirically that the proposed framework achieves strong performance on estimating the number of buildings in the United States and Africa, cars in Kenya, brick kilns in Bangladesh, and swimming pools in the U.S., while requiring as few as 0.01% of satellite images compared to an exhaustive approach.

arXiv 2112.09126, 2021.
Chenlin Meng*, Enci Liu*, Willie Neiswanger, Jiaming Song, Marshall Burke, David B. Lobell, Stefano Ermon. "IS-Count: Large-scale Object Counting from Satellite Images with Covariate-based Importance Sampling", to appear in Proc. 36th AAAI Conference on Artificial Intelligence (AAAI 2022).
Bibtex (coming soon)